
This was one of the weirdest things I had to learn when I was learning spanish. The sounds are much faster but the information density was similar. For me as an english native speaker it felt like I was listening to a machine gun at first. Eventually I trained my ear and now both languages sound the same speed.
This is also why, to me, rapidly spoken natural Spanish and Japanese sound oddly similar if I hear it out of “the corner” of my ear, so to speak.
Which is funny cause I kinda speak Spanish lol
Spanish and Japanese use the same sounds. For the most part, anyway; there are probably a few exceptions. This was unexpected and utterly blew my mind as a native Spanish speaker when I took Japanese lessons.
Take the longest, most complicated Japanese word. Write it out in romaji (Latin letters). And ask a native Spanish speaker to pronounce it. One who knows nothing of Japanese. They’ll pronounce it pretty much correctly. I was fascinated.
I recently had a conversation with a native Spanish speaker who lived in Japan and spoke Japanese fairly fluently. He said the exact same thing, it was surprising how similar they can be in this regard
I am pretty skeptical about these results in general. I would like to see the original research paper, but they usually
- write the text to be read in English, then translate them into the target languages.
- recurit test participants from
USwestern university campuses.
And then there’s the question of how do you measure the amount of information conveyed in natural languages using bits…
Yeah, the results are mostly likely very skewed.
So I did a quick pass through the paper, and I think it’s more or less bullshit. To clarify, I think the general conclusion (different languages have similar information densities) is probably fine. But the specific bits/s numbers for each language are pretty much garbage/meaningless.
First of all, speech rates is measured in number of canonical syllables, which is a) unfair to non-syllabic languages (e.g. (arguably) Japanese), b) favours (in terms of speech rate) languages that omit syllables a lot. (like you won’t say “probably” in full, you would just say something like “prolly”, which still counts as 3 syllables according to this paper).
And the way they calculate bits of information is by counting syllable bigrams, which is just… dumb and ridiculous.
I take your point without complaint, but I still think you’re an alien for saying “prolly”
I mean, probs. It’s right there. Use that if you have to
it’s pro^b - ly
Alright, but dismissing the study as “pretty much bullshit" based on a quick read-through seems like a huge oversimplification. Using canonical syllables as a measure is actually a widely accepted linguistic standard, designed precisely to make fair comparisons across languages with different structures, including languages like Japanese. It’s not about unfairly favoring any language but creating a consistent baseline, especially when looking at large, cross-linguistic patterns.
And on the syllable omission point, like “probably” vs. “prolly," I mean, sure, informal speech varies, but the study is looking at overall trends in speech rate and information density, not individual shortcuts in casual conversation. Those small variations certainly don’t turn the broader findings into bullshit.
As for the bigram approach, it’s a reasonable proxy to capture information density. They’re not trying to recreate every phonological or grammatical nuance; that would be way beyond the scope and would lose sight of the larger picture. Bigrams offer a practical, statistically valid method for comparing across languages without having to delve into the specifics of every syllable sequence in each language.
This isn’t about counting every syllable perfectly but showing that despite vast linguistic diversity, there’s an overarching efficiency in how languages encode information. The study reflects that and uses perfectly acceptable methods to do so.
Well I did clarify I agree that the overarching point of this paper is probably fine…
widely accepted linguistic standard
I am not a linguist so apologise for my ignorance about how things are usually done. (Also, thanks for educating me.) But on the other hand just because it is the accepted way doesn’t mean it is right in this case. Especially when you consider the information rate is also calculated from syllables.
syllable bigrams
Ultimately this just measures how quickly the speaker can produce different combinations of sounds, which is definitely not what most people would envision when they hear “information in language”. For linguists who are familiar with the methodology, this might be useful data. But the general public will just get the wrong idea and make baseless generalisations - as evidenced by comments under this post. All in all, this is bad science communication.
But the general public will just get the wrong idea and make baseless generalisations - as evidenced by comments under this post. All in all, this is bad science communication.
Perhaps, but to be clear, that’s on The Economist, not the researchers or scholarship. Your criticisms are valid to point out, but they aren’t likely to be significant enough to change anything meaningful in the final analysis. As far as the broad conclusions of the paper, I think the visualization works fine.
What you’re asking for in terms of methods that will capture some of the granularity you reference would need to be a separate study. And that study would probably not be a corrective to this paper. Rather, it would serve to “color between the lines” that this study establishes.
Cowards left out Navajo.
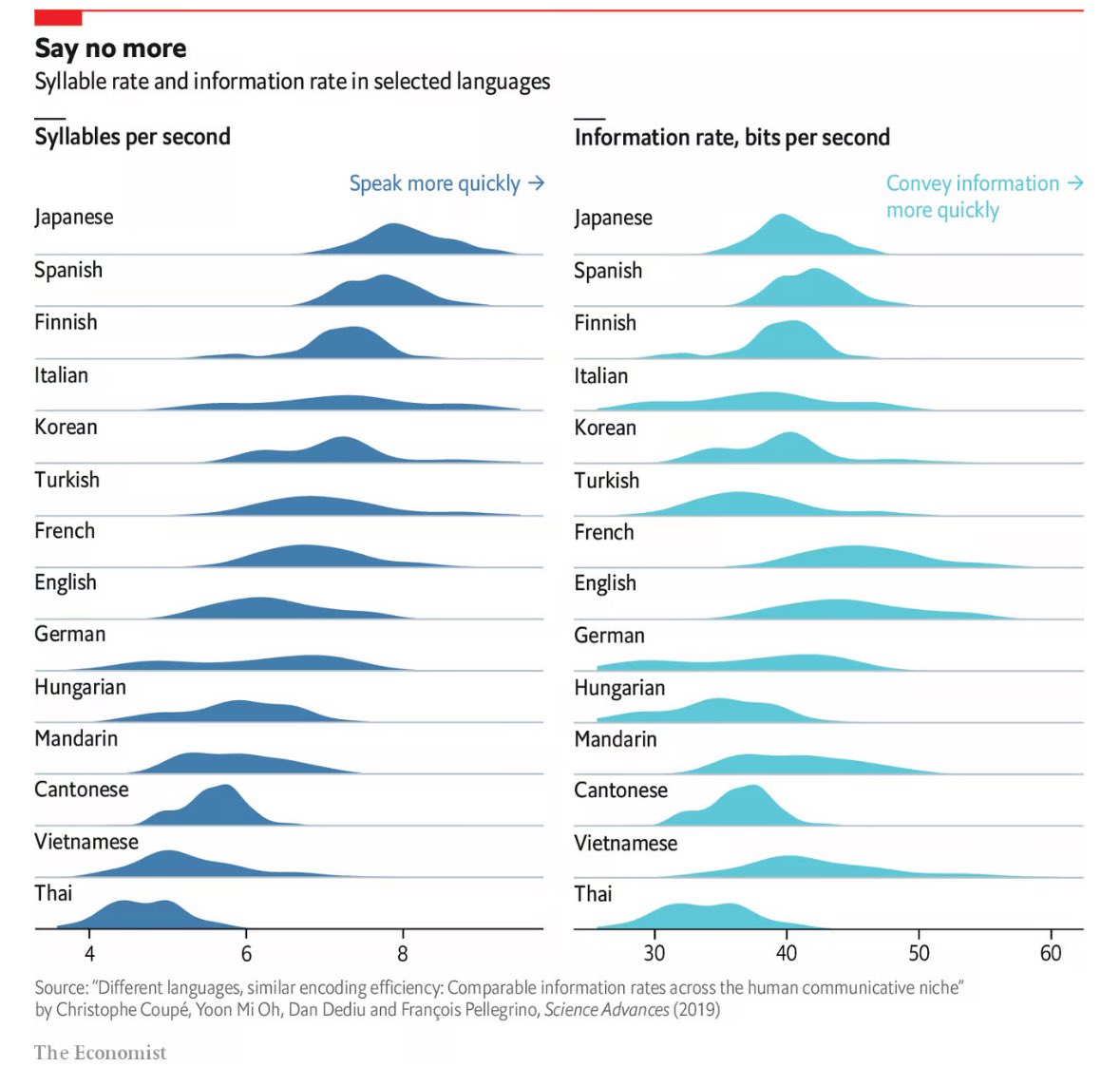
So if I’m reading this right, French (closely followed by English) tends to convey the most info per unit time?
Yes but they also utilize smell.
I think i read a study long ago, about the speed of transmiting information being faster in languagues of great empires. Sounds logical to me and matches English, French, Chinese.
What produces the stretched graphs like Italian and German? What do these humps mean?
Maybe they didn’t account for various factors like age or mood.
Moreover, Munic has 130 words per minute and dortmund has 180 words. There’s a ddifference in the dialect
https://preply.com/de/blog/sprechtempo-in-deutschland/ the numbers are just estimations and not a hard fact.
I always thought that English was an efficient language.
Yeah but 30% of the information in French are the “uhhh’s” lmao
They solved that by not pronouncing half the language.
Lmao facts
Speaking of “data is beautiful”, IMO a 2D scatter plot would be very useful for visualizing this relationship. This chart does provide the distribution for each language, as opposed to just the average, but at the expense of making correlation (or lack thereof) difficult to see.
Also, the ratio of the largest to the smallest value for syllables per second and for bits per second appears to be fairly similar. I have to eyeball values but it looks like Japanese : Thai is 8.0 : 4.7 for syllables per second (so 1.7) whereas French : Thai is 48 : 34 (so 1.4) for bits per second.
For each language, the distribution of syllable rate looks very much like the distribution of bit rate. I would like to see a chart of bits per syllable. Oh, and I wonder how this affects reading speed and the rate of information transfer via reading, especially for different spoken languages that use similar written characters.
Wonder how Thai is the zipfile of languages.
It is multiplexed with five tones and a variety of different registers to signify relationship, status, and variable interplay between the two based on situation.
- University Thai language learner, linguist, and professional Thai reading, writing, speaking in Thailand for several years
deleted by creator
Italian has a wildly different set than everyone else pretty much.
Wollen sie etwa behaupten, die Informationsübermittlungsgeschwindigkeit der deutschen Sprache sei unterdurchschnittlich? So eine Unverschämtheit!
It’s long been suspected that Koreans are really fast with rhythm games and have high APM because of their language getting to the point faster.
Syllables can vary in length. Japanese has very short syllables while English has rather long ones. Counting phonemes would make more sense
deleted by creator
On the other hand it looks almost too normal. Odd.
It could indicate bias on the part of the researchers. I haven’t read their methodology, but in my amateur study of languages, some languages have some interesting tricks for communication that don’t translate to English well or efficiently. If English was used as the baseline, then the study ma not incorporate some of the neat things other languages can do as points to measure.
Mandarin has a word particle to communicate “completed action”. This is used instead of conjugating verbs for tenses. Example: in English you might say:
“I went to the shop” 5 syllables
In Mandarin the literal translation back to English would be:
“I go to the shop [completed action]” 5 syllables
For the two measures listed of essentially Information Density and Speech Velocity, this benefit wouldn’t show up, but if you’re measure for something like Encoding and Decoding Burden (I’m making up these terms), then Mandarin could rank higher.
Could be bias. But, I wonder if it could be because English has borrowed so much from other languages.
It’s also interesting that English and French look so similar in the graphs. Both, have been the de facto international language for a long time.
That was the issue I had with my elementary school spanish teacher. He spoke so fast that you just couldn’t latch onto anything. It just sounded like DDDDDDDDDDDDDDDDS aqui. DDDDDDDDDDDDDDDDRS agostos.






{kind=link}